
* TIL/개념: 최대한 공식 문서 & 책을 기반으로 배운 내용을 정리
* 현재 취준생으로 풋내기 개발자가 쓰는 글입니다.
* 그러니 조언과 지적 및 훈수는 언제나 환영입니다! 댓글로 많이 달아주세요!
프로세스의 각 주소 영역에 대하여
1. 일반적인 프로세스 메모리 주소 영역
프로그램이 CPU에서 명령을 수행하기 위해서는 해당 명령을 담은 프로그램의 주소 영역이 메모리에 올라와 있어야 한다.
프로그램이 실행되면 다음과 같은 두 가지 일이 발생한다.
1. 디스크에 존재하던 실행 파일이 메모리에 적재된다.
2. 프로그램이 CPU를 할당받고 명령을 수행 중이다.
2번을 위해서는 명령을 담은 프로그램의 주소 영역은 메모리에 올라와 있어야 한다.
이 때 주소 영역이 오늘 살펴볼 프로세스의 메모리 구조다.
1.1. 일반적인 프로세스 메모리 주소 영역
일반적으로 주소 영역은 크게 코드(code), 데이터(data), 힙(heap), 스택(stack) 영역 4가지로 나뉜다.

- code: 프로그램 함수들의 코드가 저장되는 영역. CPU에서 수행할 수 있는 기계어 명령(ex. 2진수나 16진수 파일) 형태로 변환되어 저장
- data: 전역 변수 등 프로그램이 사용하는 데이터를 저장
- data 영역을 또한 bss와 data 영역으로 나눌 수 있음
- bss 영역은 초기화된 데이터, data 영역은 초기화 되지 않은 데이터가 저장
- heap: 동적으로 할당된 변수가 저장되는 영역. 메모리의 낮은 주소에서 높은 주소로 할당
- stack: 지역 변수, 매개변수, 리턴값을 저장되는 영역. 함수가 호출될 때 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터를 임시로 저장하는 데 사용되는 공간. 메모리의 높은 주소에서 낮은 주소로 할당
code 영역과 data 영역에 있는 데이터는 프로세스가 실행되기 전에 이미 위치와 크기가 결정되었으므로 정적 할당 영역.
반면, stack 영역과 heap 영역에 있는 데이터는 그렇지 않고, 크기가 늘어났다가 줄어들 수 있어서 동적 할당 영역이라고 부른다.
또한 이 같은 메모리 구조는 사용환경에 따라 달라질 수 있다.
2. 스택 영역
2.1. 스택 영역의 동작 과정
스택 영역은 함수가 호출될 때 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터를 임시로 저장하는 데 사용한다.
함수가 호출되면 스택에는 함수의 매개변수, 호출이 끝난 뒤 돌아갈 반환 주소값, 함수에서 선언된 지역 변수 등이 저장된다. 이 스택 영역에 차례대로 저장되는 함수의 호출 정보를 스택 프레임(stack frame)이라고 한다.
이 스택 프레임 덕분에 함수의 호출이 모두 끝난 후에 호출되기 이전 상태로 돌아가기 쉬워진다.
만약 main() 함수 안에서 func1()를 호출하고, func1()에서 func2()를 호출했다고 가정해보자.
다음과 같이 말이다.
<cpp />
void main() {
func1()
}
void func1() {
func2()
return
}
void func2() {
return
}
아마도, stack 영역은 다음과 같이 될 것이다.
함수를 호출할 때마다 매개변수, 반환 주솟값, 지역 변수가 스택에 쌓이고 있다.
main() → func1() → func2()로 호출이 되어서 순서대로 쌓이고 있다.
이 중 가장 먼저 반환하는 함수는 func2() 다.
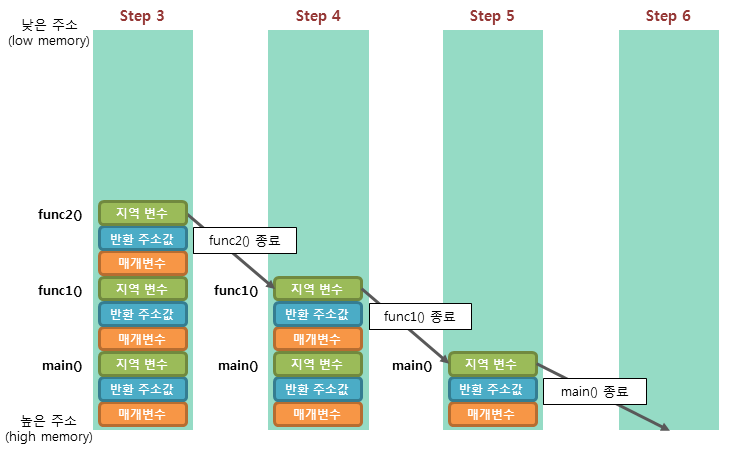
각 함수가 종료되니 그 함수의 스택 프레임이 스택에서 제거가 됨을 볼 수 있다.
2.2. 함수 호출을 Stack 영역으로 한 이유
함수 호출을 Stack 영역으로 했을 때 가질 수 있는 이점은
첫 번째로, 함수를 어디서 호출했는지를 알 수 있다.
돌아올 메모리 주소를 저장하기 때문에 호출이 끝나면 쉽게 호출된 곳으로 넘어갈 수 있게 된다.
두 번째는 변수 활용 범위에 영향을 미치는 scope를 구현할 때 사용된다.
스택 영역에는 지역 변수도 들어가기 때문에 쉽게 scope 안에서 활용되는 변수를 파악할 수 있다.
2.3. StackOverFlow
만약 스택이 만약 계속해서 쌓이면 주소가 작아지면서 결국 힙 영역의 최고 주솟값에 가까워지게 되는데,
너무 쌓이면 힙 영역을 침범하게 된다. 이를 StackOverFlow라고 한다.
주로 재귀호출에 의해 발생하는 편이다.
2.4. StackPointer
또한 중앙처리 장치 안에는 스택에 데이터가 채워진 위치를 가리키는 레지스터인 스택 포인터(Stack Pointer)를 가지고 있다. 즉, 스택포인터가 가리키고 있는 곳까지 데이터가 채워진 영역이다.
맨 처음 메모리에서, 스택에 아무 값도 없기 때문에, 스택 포인터는 힙의 최대 주소값과 스택의 최대 주소값을 합친 값이다.
즉, 맨 처음이 가장 스택 포인터가 크다.
스택에 새로운 데이터가 추가되면 스택 포인터는 감소하고 스택에 데이터가 제거되면 스택 포인터는 증가한다.
3. 힙 영역
3.1. 힙 영역의 동작 과정
힙 영역은 동적 할당 시에 사용하는 공간이다.
직접 메모리에서 동작하는 과정을 malloc()으로 예들 들어보겠다.
<cpp />
char* p1 = malloc(sizeof(int) * 4) // malloc(16)
int형 변수는 4byte이므로, 총 16byte가 할당되어야 한다.
이제 할당할 수 있는 공간을 힙에서 찾는다.

힙을 보니 사용할 수 있는 공간이 보이면 여기가 비었네! 하고
해당 공간의 시작 주소를 가지고 온다.
그리고 그 시작 주소는 멤버 변수, 즉 스택에 들어가게 되고
힙에는 그 시작 주소에 가서 공간을 할당한다.
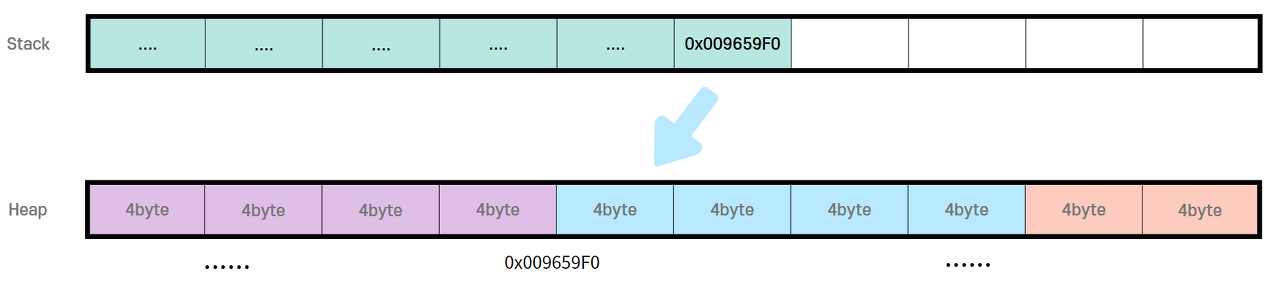
free()할 때는 스택에 있는 시작 주소를 통해
Heap의 해당 주소로 가서 Free()를 시켜주고, 시작 주소를 가지고 있던 스택의 변수 또한 없애주면 끝이다.
3.2. 메모리 누수(Memory Leak)
그럼 여기서 만약 free()를 해주지 않으면 어떻게 될까?
스택은 함수의 반환과 동시에 사라지는, 말 그대로 임시 공간이므로
가지고 있던 시작 주소는 영영 사라져버린다...
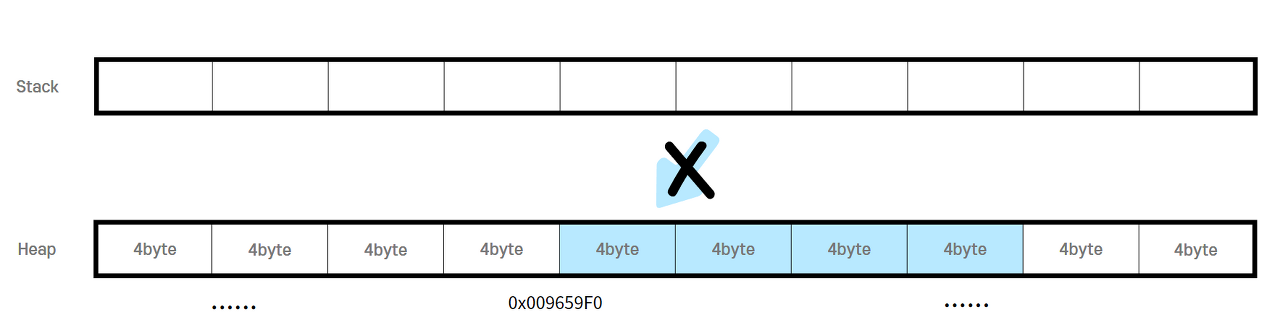
만약 func1()라는 함수에서 동적으로 공간을 할당했는데,
이를 free()하기도 전에 return 한다면 스택에 쌓여있떤 모든 변수는 사라진다.
즉, 시작 주소를 가리키고 있던 포인터 변수 또한 사라진다.
결국 힙에서 차지하고 있던 해당 공간은 사용하고 있지만,
가리키는 변수가 없어 사용할 수 없는 것이다.
이 문제를 바로 메모리 누수(Memory Leak)라고 한다.
(다만 이는 C와 C++에서 해당하고, 최근 나온 언어는 대부분 이런 문제를 알아서 해결해준다. ex. GC)
3.3. HeapOverFlow
Stack Overflow처럼, 너무 데이터가 넘쳐서 Stack 영역을 침범하는 HeapOverFlow다.
주로 사용자가 직접 메모리를 소멸시키지 않았을 경우 발생한다.
3.4. 단편화
단편화는 Heap에서 동적 할당하는 공간을 찾을 때 발생하는 문제점이다.
크게 내부 단편화와 외부 단편화가 있다.
- 내부 단편화: 메모리 공간이 일정 크기로 나뉘어 있을 때, 메모리가 할당되고 남은 공간이 너무 작아 사용할 수 없는 상태
- 외부 단편화: 들어오는데로 동적으로 할당할 때, 공간에 데이터가 순서대로 할당되고 일부가 반환되어 공간이 있지만, 새로 할당된 객체들이 들어오기엔 너무 작은 상태
그렇다면 이렇게 빈 공간이 있음에도 공간을 할당할 수 없는 문제가 발생하지 않도록 하는 효율적인 방법은 무엇인가?
아이디어로 저장소 관리 알고리즘인 최초 적합 및 최적 적합, 페이징(Paging), 세그멘테이션(Segmentation)을 활용할 수 있다.
- 최초 적합(First-Fit): 데이터가 들어갈 수 있는 첫 번째 free 블록을 선택하는 방법.
- 최적 적합보다는 효율이 떨어져도, 빠르다.
- 최적 적합(Best-Fit): 데이터가 들어갈 수 있는 가장 작은 free 블록을 선택하는 방법.
- 최초 적합보다는 느려도, 효율성이 좋다.
- 페이징과 세그멘테이션
- 페이징: 외부 단편화 해결, 내부 단편화 존재
- 관리하는 free-list 대신 동일한 크기의 블록, 즉 페이지로 나눈 후에 맵핑 테이블로 관리하는 방식
- 연속적이지 않은 공간도 활용할 수 있어 외부 단편화 X
- 페이지 단위에 알맞게 꽉 채워 쓰는 게 아니므로 내부 단편화 O
- 세그멘테이션: 외부 단편화 문제, 내부 단편화 해결
- 메모리를 서로 크기가 다른 세그먼트로 분할해서 free list를 관리하는 방식.
- 각 세그먼트는 연속적인 공간에 저장되어 있다.
- 필요한 메모리 만큼 할당해주기 때문에 내부 단편화 X
- 여전히 중간에 프로세스가 메모리를 해제하면 생기는 외부 단편화 O
- 페이징: 외부 단편화 해결, 내부 단편화 존재
4. 요약
- 코드 영역
- 프로그램 함수들의 코드가 저장되는 영역. CPU에서 수행할 수 있는 기계어 명령 형태로 변환되어 저장
- 데이터 영역
- 전역 변수 등 프로그램이 사용하는 데이터를 저장하는 영역
- 힙 영역
- 동적으로 할당된 변수가 저장되는 영역
- 메모리의 낮은 주소에서 높은 주소로 할당
- 메모리 누수: 만약 동적 할당 후 해제하지 않으면 공간은 차지해도 가리키는 변수가 없어 사용할 수 없게 된다.
- HeapOverFlow: 힙에 데이터가 넘쳐서 스택 영역을 침범할 때
- 단편화: 힙에서 빈 공간이 있음에도 공간을 할당할 수 없는 문제가 발생
- 외부 단편화, 내부 단편화 존재
- 최초 적합, 최적 적합, 페이징, 세그멘테이션 등 활용 가능
- 스택 영역
- 지역 변수, 매개변수, 리턴값 등을 저장하는 영역
- 함수가 호출될 때 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터를 임시로 저장하는 데 사용되는 공간
- 메모리의 높은 주소에서 낮은 주소로 할당
- 스택 프레임(stack frame): 스택 영역에 차례대로 저장되는 함수의 호출 정보
- StackOverFlow: 스택에 데이터가 계속 쌓여서 힙 영역을 침범할 때
- StackPointer: 중앙처리 장치 안에 존재하는 스택에 데이터가 채워진 위치를 가리키는 포인터.
5. 참고 자료
[개인블로그] 프로그래밍 언어론 3-2-3강, 메모리할당-힙기반 할당(Heap-Based Allocation)
6. 마치며
이후 JVM 메모리 구조 → GC 순으로 포스팅
'CS > OS' 카테고리의 다른 글
| [TIL/개념] 캐시(cache) (0) | 2023.05.27 |
|---|
